The problem with durable execution workflows
All workflow execution engines, durable workflows, and whatever other catchy names people come up with share one big problem: they all need to set a "higher level execution context" to ensure determinism of workflow.
In my opinion, this new execution context is not explained well enough and causes a lot of friction when you're developing with these tools.
Lets explore how a durable execution engine works to better understand what could be improved.
Most durable codebase, running through durable execution engine share the same architecture. High level code execution flow is controlled by a workflow, which is invoking steps. Not all the code of durable codebase must run inside of the engine. Most of the time, read only code is not in the “durable” path.
A workflow is the top-level orchestration unit that defines the complete business process. It consists of multiple steps, activities, task that execute according to the workflow code. The durable engine managing state, retries, scale and coordination between steps. The workflow tells the engine what to run, when and how.
Workflow code will be replayed many time in the life time of the workflow instance. Indeed, everytime the workflow needs to wait for a step result, for some time, for a signal, the “real process” running the workflow code is killed : it’s inefficiant to keep a piece of code running waiting for no reasons. (This would also makes the execution statefull, which must be avoided at all cost when developping large applications).
When it's time to continue execution, the workflow code runs from the start. Old functions are "replayed" instead of executed again. This is why determinism matters: if step results changed with each invocation, the workflow would become incoherent.
The workflow is the cooking recipe of your application, it is controlling the flow of execution. We need workflow to be deterministic to ensure the execution can be repeated multiple times. Workflow are the high level overview of the program flow.
Lets considere a very simple “pro plan 30 days trial” workflow :
function proTrialFlow(user: User) {
addPermission(user, 'pro');
let startTrialEmail = await generateStartTrialEmail(user);
sendEmail(startTrialEmail);
waitFor('30 days');
let trailEndedEmail = await generateTrialEndedEmail(user);
removePermission(user, 'pro');
sendEmail(startTrialEmail);
}This workflow has multiple steps. None can fail or be repeated multiple times. The execution must happen once and succeed. Let's break down how most durable workflow engines execute code.
All code executed in a workflow must run through steps. Workflow code only controls the execution flow; it doesn't do the actual processing.
Steps are responsible of doing the actual work. A step is like a big memoized function. When you invoke it and its execution is a success, the result is cached using a key composed of the workflowExecutionId , stepId and functionArgs . This is key for a durable execution. You only run the processing code once, but can replay the step as many time as you want.
The cached result of the function is then returned for every next workflow code invocation, this ensure the workflow variable stays coherents, hours later the last execution. Contrary to popular belief, most durable engine do not store snapshot of the memory, or execution pointer. They just replay the code, using cached function result. Possible thank to the purity of the workflow function and the memoized nature of steps.
This sequence diagram tries to explain how the workflow would run in a very simplified durable worflow engine. The dotted line may be queued, plain line could not.
Even if trigger.dev is a real durable execution engine, they are not really following the architecture I just described. Trigger.dev offers the same result as the other durable engine without having a workflow component.
Instead of replaying all of the code at each new instantiation of the workflow, trigger.dev does a snapshot of the process running the code using CRIU (Checkpoint/Restore In Userspace). This dumps the process internals to a file which can be resumed later.
This ease the developper experience, because he doesnt have to think about anything else than writting code, but will have limitation with ETLs and data intensive applications. This architecture blurs the line between “real code” and durable code, which have pro and cons.
A step is an individual unit of real processing within a workflow. Steps are the building blocks of workflows : they can execute all “real code” : fetching APIs, transforming data, any operation really.
The execution engine tracks the completion status of each step, enabling features like automatic retries on failure, state persistence, and the ability to resume workflows from the last completed step rather than restarting from the beginning.
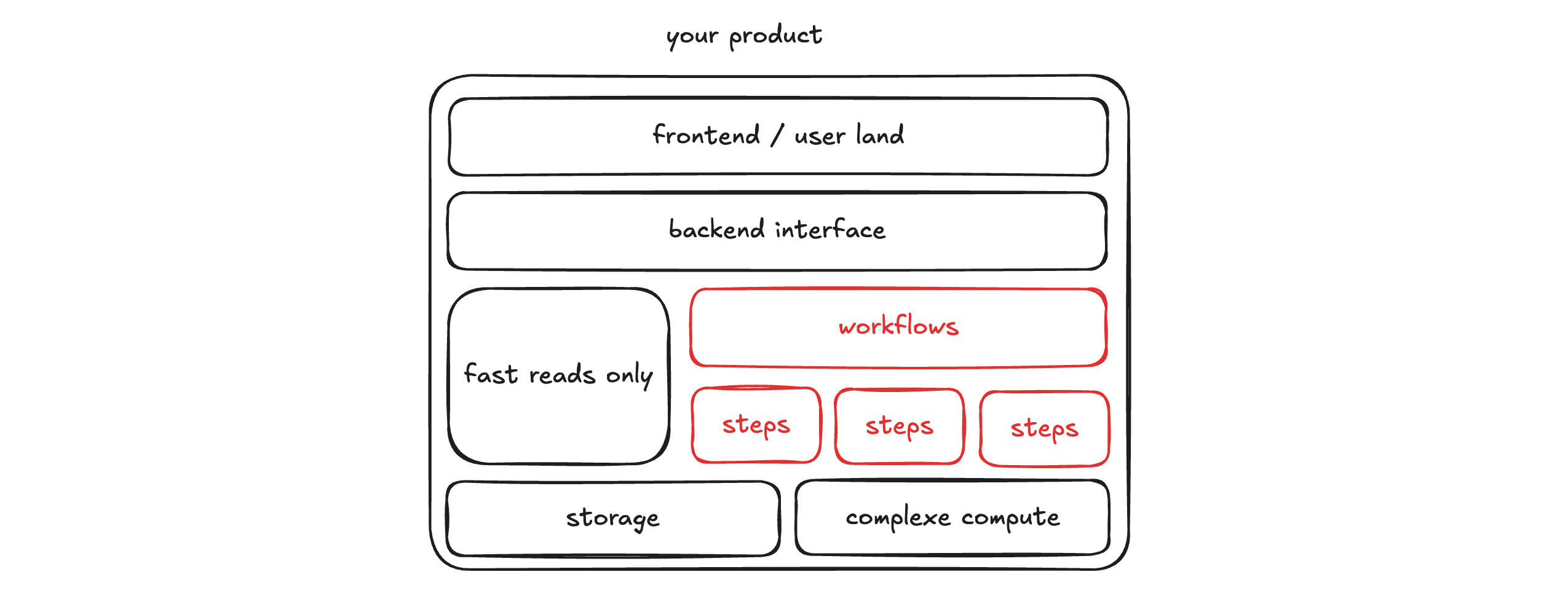
In your codebase, you will have other pieces of code, some of it will be used to orchestrate and coordinate the workflows, because workflow are pretty much infrastructure.
Durable workflows cannot be called from the front-end, so you will need to have an interface between the user and this workflow engine.
This interface can also enable a fast read only controller, responsible of only getting data (data send to the user should not be heavily transformed on the read path of your application : only authentification and authorization checks should be performed here).
Durable code should be highly transactionnal, everything else may stay in the non durable part of the codebase.
All durable workflow engines let users write workflow code in their programming language. This is great for developer experience, but it creates significant constraints on the execution engine.
As mentioned earlier, workflows must be pure functions. If a workflow can mutate data without tracking, the engine cannot provide a truly deterministic runtime environment. Pure functions are native to languages like Haskell or OCaml, but most durable execution enthusiasts typically prefer TypeScript, Go, or Python—languages where purity isn't guaranteed out of the box.
This is where the real challenge begins for durable workflow engines.
To solve the purity problem, workflow execution engines cheat by using sandboxes. In these controlled environments, the engine can ensure the code will not call non-deterministic code, because most of these functions are banned, not imported, or patched using deterministic ones (like here in Vercel's workflows).
Vercel's vm patches non-deterministic functions such as Date or crypto:

Patching reduces non-determinism in workflow execution. When you instantiate a new workflow, the orchestrator sets the random generator seed, the date, and most other non-deterministic functions; ensuring the result stays the same when the workflow code is replayed later.
Overriding such core functions could lead to catastrophic bug if the code was shared with “normal code”. For example, setting the seed of crypto will break most security protocol.
Sandboxes are use to ensure only the workflow is using patched functions (and not all other processes), for example NodeJS provide a package made for that : node:vm .
This makes the workflow almost pure (most of basic Node.js's APIs are unavailable, package are whitelisted…), at the cost of running the code in a different environment than the one currently running the steps code.
Durable engines try to emulate an environment as close as possible to the steps environment, but it will never be perfect—this one cannot have side effects.
At their recent conference, Vercel introduced a new "workflow dev kit"—their solution to the durable execution problem. The big innovation isn't the engine their workflows run on, but rather the developer experience they introduced to build durable code :

Inside of importing the workflow in the worker (like in Temporal.io), or wrapping the workflow into functions (like in Inngest), they re-used a concept they love a lot : the compiler directives.
This is a new concept for the TS community, even if it was introduced a few years ago with the "use strict" , it’s only the recent "use server" and "use client" which popularized it.
The new directive "use workflow" allow the developper to create a workflow. When the transpiller sees a "use workflow" directive at the top of a function, the transpiller will transform this function into a workflow.
This solution has sparked big debate inside of the TS community :
The main criticisms around this pattern are : the lack of workflow parameters, the lack of typing of the workflow and the “magical “ feeling of the directive.
Directive may sounds like a new idea, but really they are just compiler macros, wildly use in other programming languages (see rust or C++). I don’t really understand how they can be that bad when used in TS.
Regarding the other points, I tend to agree with the community. In Temporal you can configure multiple parameters to control how your workflow retries and reacts to failures. use workflow doesn't offer these APIs (or offers them by setting properties on the workflow function, which is weird, even for TS).
Many people also complain about the lack of type safety: when you call a workflow function (a normal function with a directive inside), you can't tell that it's a workflow function rather than a normal one. The coloration of the workflow function is unclear.
But, I think we're all missing the most important one—the one all current solutions avoid: the switch of environment runtime.
This is the most important problem we should address when creating a workflow. At the moment, I think the use workflow solution is the only one really trying to solve it. Having the directive inside the workflow function means the developer knows this function is a workflow definition, helping reduce overall complexity and clarify the boundary.
But this solution is not perfect, and I dont really think all durable engine will tend to the trigger approch of snapshotting all of the process everytime the execution needs to be stopped.
Scoping and function coloring is the biggest problem to solve in durable execution. Developers need to quickly know whether a function is a durable workflow or not : whether they can expect normal execution or if the code will run in a sandboxed environment.
More than syntactic sugar, we need a clear border between "normal code" and "durable workflow code". Right now, both pieces of code look identical but behave completely differently.
My solution would involve creating a new transpilled syntax for workflows. Like jsx , or like all the other syntaxes introduced by frontend frameworks.
The problem is not the same, JSX was created to simplify the life of developpers and make the React code closer to “normal HTML”. But this shows we can do it. And I really do think the simplicity of the syntax is the main reason why we are not writting jquery code anymore.
// signup.wts (workflow ts)
// this would be normal typescript but with stricter linter rules
import { readFileSync } from "node:fs" <-- lint error
// some libraries could be instanciated by default
const inputSchema = z.object({})
// we could have some special keywords like the workflow
// we could also create a new syntax to define some workflow parameters
workflow proTrialFlow(args: Workflow) ({
retry: 3
}) {
addPermission(user, 'pro');
let startTrialEmail = await generateStartTrialEmail(user);
sendEmail(startTrialEmail);
waitFor('30 days');
let trailEndedEmail = await generateTrialEndedEmail(user);
removePermission(user, 'pro');
sendEmail(startTrialEmail);
} Having a new superset of typescript would also allow the creating of specialized developpers tools such as linter or even debuggers. A durable workflow debugger would be able to directly debug production data instead of local dummy data.